Pipeline Health Estimator
Input your stack size and incident history. Get an honest estimate of what Pipeline saves you per sprint.
Get a full audit of your actual pipeline with personalized recommendations.
Works with your stack.
All of it.
One config file. Pipeline connects to every layer of your data stack and starts catching issues in under 10 minutes.
Real-time schema drift detection across all databases, schemas, and tables. Catches column drops, type changes, and constraint mutations before your dbt models break.
Partition freshness monitoring, slot usage anomalies, and streaming insert validation.
Parses your manifest.json live. Catches test failures, model staleness, and dependency graph breaks before CI does.
Zombie DAG detection, task SLA monitoring, and backfill anomaly alerts. Kills stuck tasks before they block the whole graph.
Stage-level lineage tracking and executor failure pattern detection across batch and streaming jobs.
Unity Catalog schema monitoring, Delta table freshness, and job cluster anomaly detection.
Engineers who stopped guessing.
From 50-model startups to 2,000-model platforms — Pipeline runs in production across every scale.
"We had a column drop in our Snowflake orders table at 11 PM on a Thursday. Pipeline caught it in 47 seconds and paged our on-call before a single dashboard went red. That's the first time in three years our data lead slept through a deploy."

"Our dbt project has 847 models. Before Pipeline, every sprint had at least two incidents that traced back to schema drift we didn't catch in CI. Now we catch them in staging."
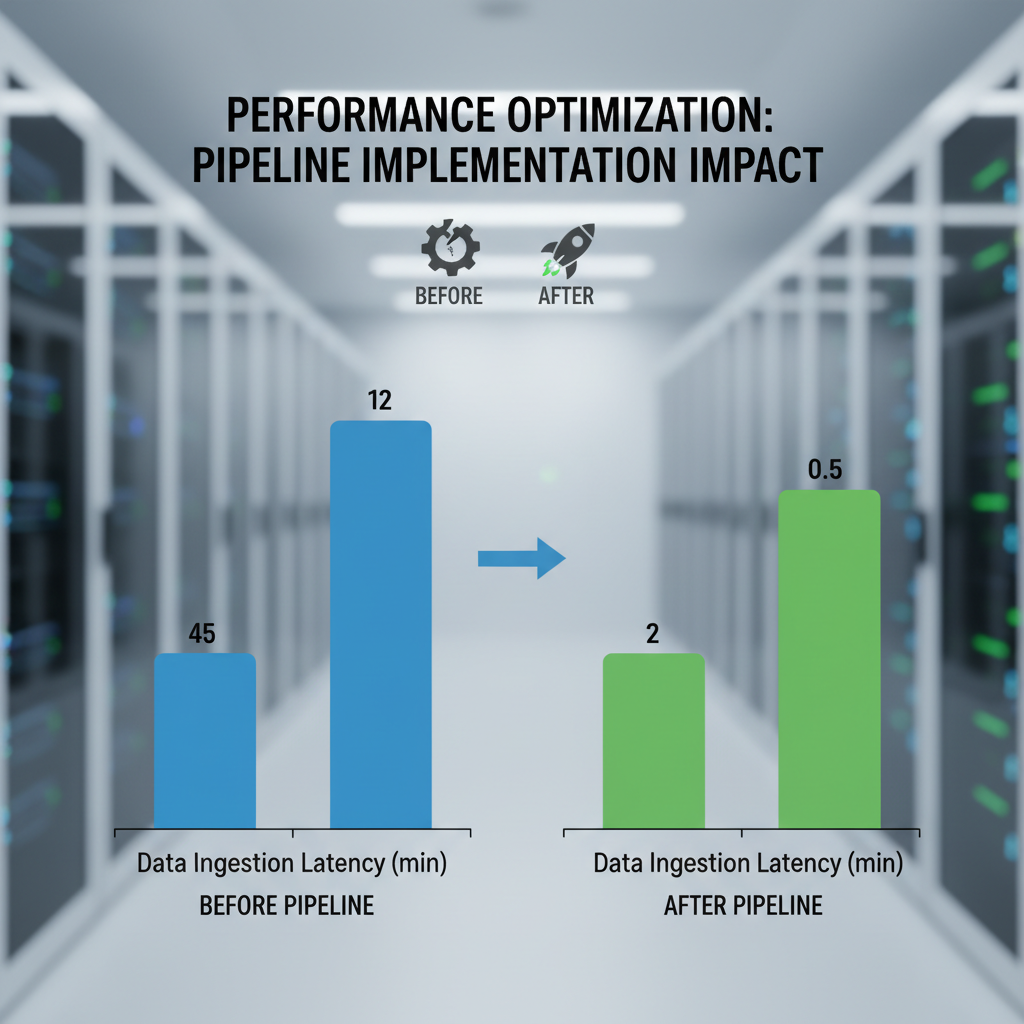
"Pipeline replaced three separate monitoring tools we were duct-taping together. The YAML config took 12 minutes. The zombie DAG detector alone saved us 8 hours in the first week."

"I had to present pipeline reliability numbers to our VP of Product. Pipeline gave me a freshness SLA dashboard I could point to in 10 minutes. That conversation used to be a nightmare."

One agent. Every layer.
Zero blind spots.
Pipeline sits between your data sources and your consumers — a single health engine that speaks to every tool in your stack.
Deploy in Your Stack
Get a hosted sandbox connected to your actual warehouse. Pipeline running in your environment in under 10 minutes.